It’s here! All subscribers to Fintech Prime Time can access the full 2026 State of Fintech report via the F-Prime Fintech Index.
But first, save your spot with the F-Prime team for a virtual presentation and discussion of our findings on Tuesday, February 24 at 12pm ET / 9am PT.

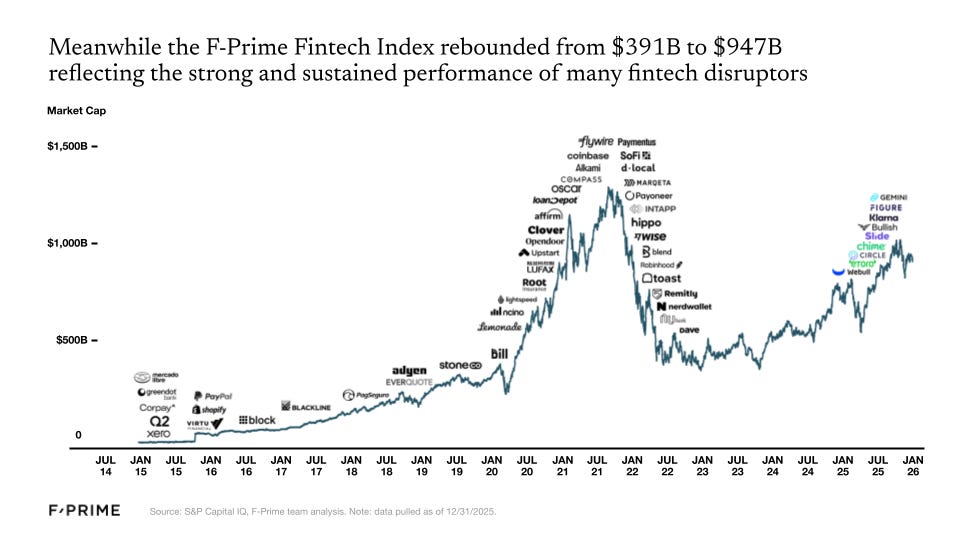
The fintech industry has experienced its ups and downs over the last five years. In 2021, the F-Prime Fintech Index market cap rose to $1.3T, followed by a swift correction in 2022 when the Index bottomed out below $400B. The effects of that correction lingered into 2023, but started a slow and steady rebound in 2024. By the end of 2025, the F-Prime Fintech Index was almost back to $1T.
At the same time, 2025 was the year we could definitively say three things. First, the fintech investments of the last decade have produced multiple new industry giants that lead in their respective categories — Nubank, Affirm, Stripe, Toast, and Robinhood, to name a few. Second, crypto has earned its seat next to traditional finance (TradFi). We expand on both these points in the State of Fintech report. Finally, 2025 was not the year of AI in financial services, at least relative to its early adoption in other industries and functions like coding, customer service, and legal. However, it is coming quickly and we anticipate future State of Fintech reports will show a lot more adoption.
The first months of 2026 brought sharper market discipline than many expected, eliminating over 80% of the Fintech Index market cap gain between year-end 2024 and 2025. Despite the Q1 2026 sell-off, we believe financial services providers will ultimately benefit more from AI than be disrupted by it. The outlook is less forgiving for legacy technology vendors serving financial institutions, many of whom risk being displaced by native agentic architectures. For now, however, public markets appear to be painting the sector with a broad brush.
A Thaw in Public Fintech Markets
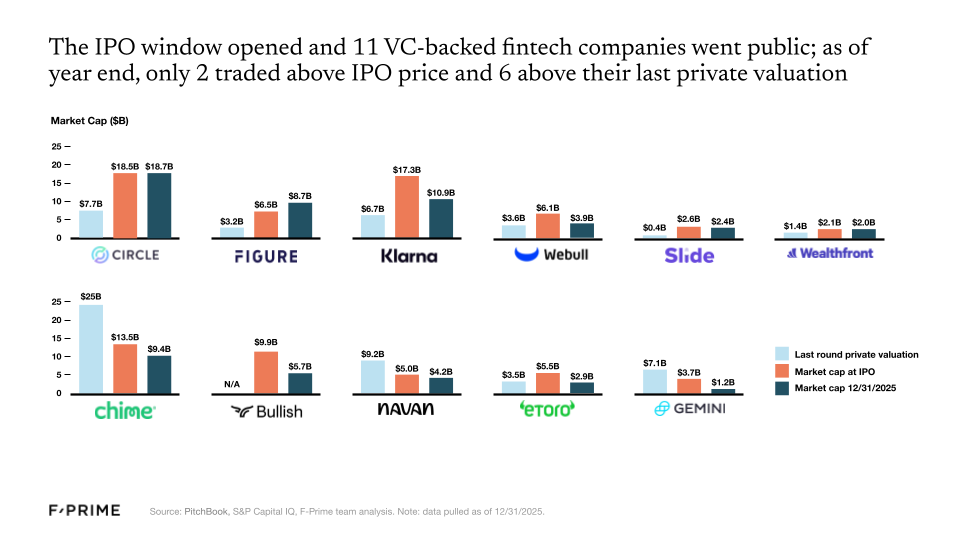
16 fintech companies went public in 2025, 11 of which were VC-backed. Despite subpar performance for many of these companies in the public markets (as of 12/31/2025 only two traded above their IPO price, and six traded above their last private round valuation), the IPO window is officially open. More public listings are on their way — already three more in 2026!. Meanwhile, fintech M&As are showing even greater signs of health, rebounding to pre-2021 levels.
Revenue multiples also continue to rise — over the last two years, investors have prioritized so-called “goldilocks” companies that are neither growing too fast nor too slow while approaching profitability. As for the companies comprising the F-Prime Fintech Index, fundamentals continue to strengthen. They grew at an average of 29% over the last year, with every sector seeing meaningful increases in net income margins since the growth-at-all-costs mindset that characterized the 2021 peak.
A New Generation of Financial Services Giants
The last 15 years have produced new industry heavyweights. Much like Uber, PayPal, and Square were initially dismissed yet came to lead their respective industries, so too have companies like Nubank, Affirm, Stripe, Toast, and Robinhood become leaders in theirs.
If measured against US standards, Revolut, SoFi, and Nubank would now rank in the top 1.5% of American banks if they were chartered in the US. Each has nearly $30B in deposits. In payments, Stripe and Adyen were tied for fifth place in the list of top global merchant acquirers, each with around $1.4T in TPV, while Toast processes an estimated 15% of the restaurant industry’s payment volume.
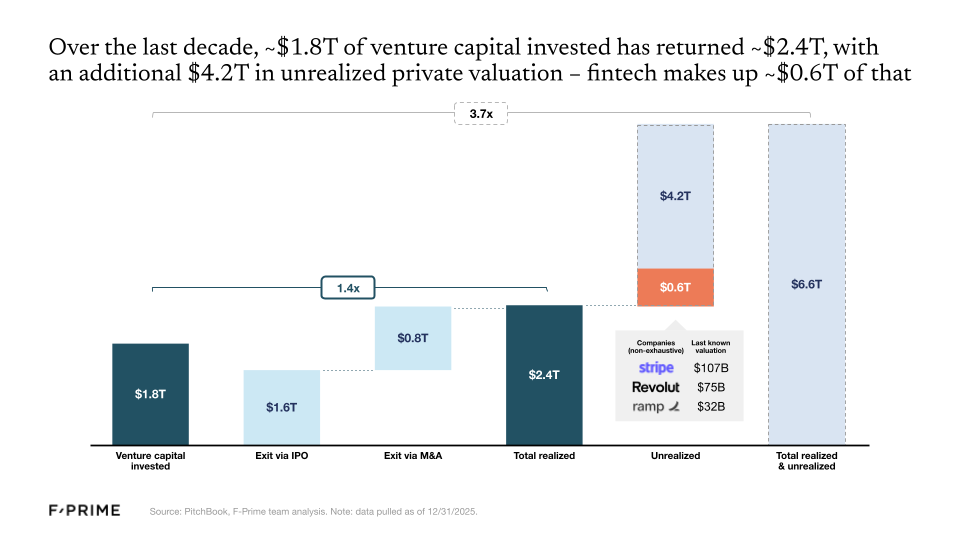
So the fintech wave of the 2010s has now officially produced its first generation of giants, but there are many others still waiting in the wings. Roughly $1.8T of venture capital has been invested in the category over the last decade, returning an estimated $2.4T. But $4.2T remains locked up in innovative private companies, with fintech making up around $0.6T of that total, including some of the most valuable fintech companies like Stripe ($107B), Revolut ($75B), and Ramp ($32B).
Crypto Grows Up
As of 2025, we can officially say that the crypto industry has earned a front-row seat alongside TradFi, crossing a number of thresholds that show real integration with the broader economy. For starters, issuers like Blackrock and Fidelity contributed to a total of more than 75 new crypto ETFs launched in 2025. This marks a structural shift in the makeup of the crypto market. At the same time, regulators’ posture towards crypto meaningfully shifted in 2025, paving the way for further institutional adoption moving forward.
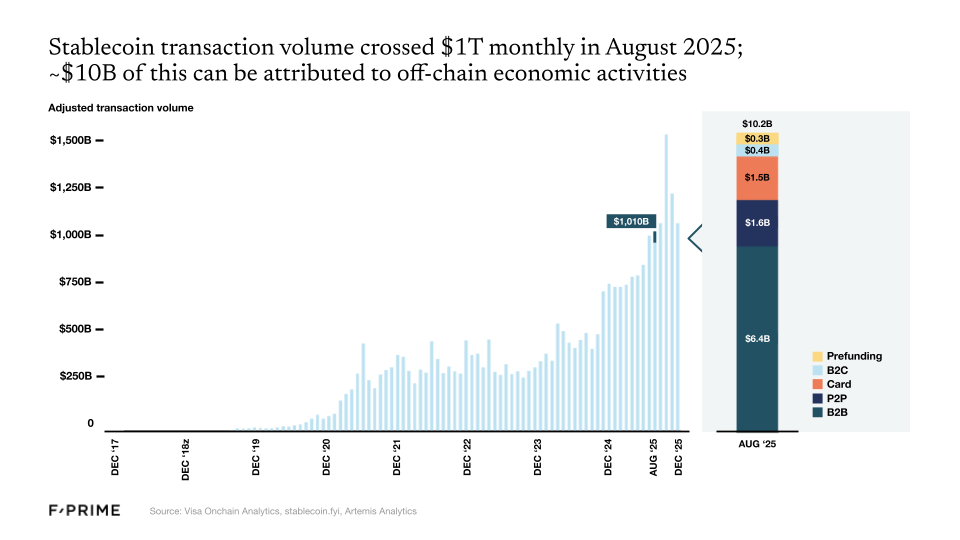
And then there are stablecoins, which crossed $1T in monthly volume in 2025. Stablecoins may be the best example of a “killer use case” in crypto. Stablecoins could reduce the cost of remitting $200 from $20-30 via bank transfer to less than $1.
Following the initial adoption of stablecoins and tokenized treasuries, we can now wonder whether any financial asset will not be tokenized in the next 10 years. The next few years will see an expansion of tokenization across a wider spectrum of asset classes, including real estate, private credit, and other private funds.
AI Has Not Transformed Fintech (Yet)
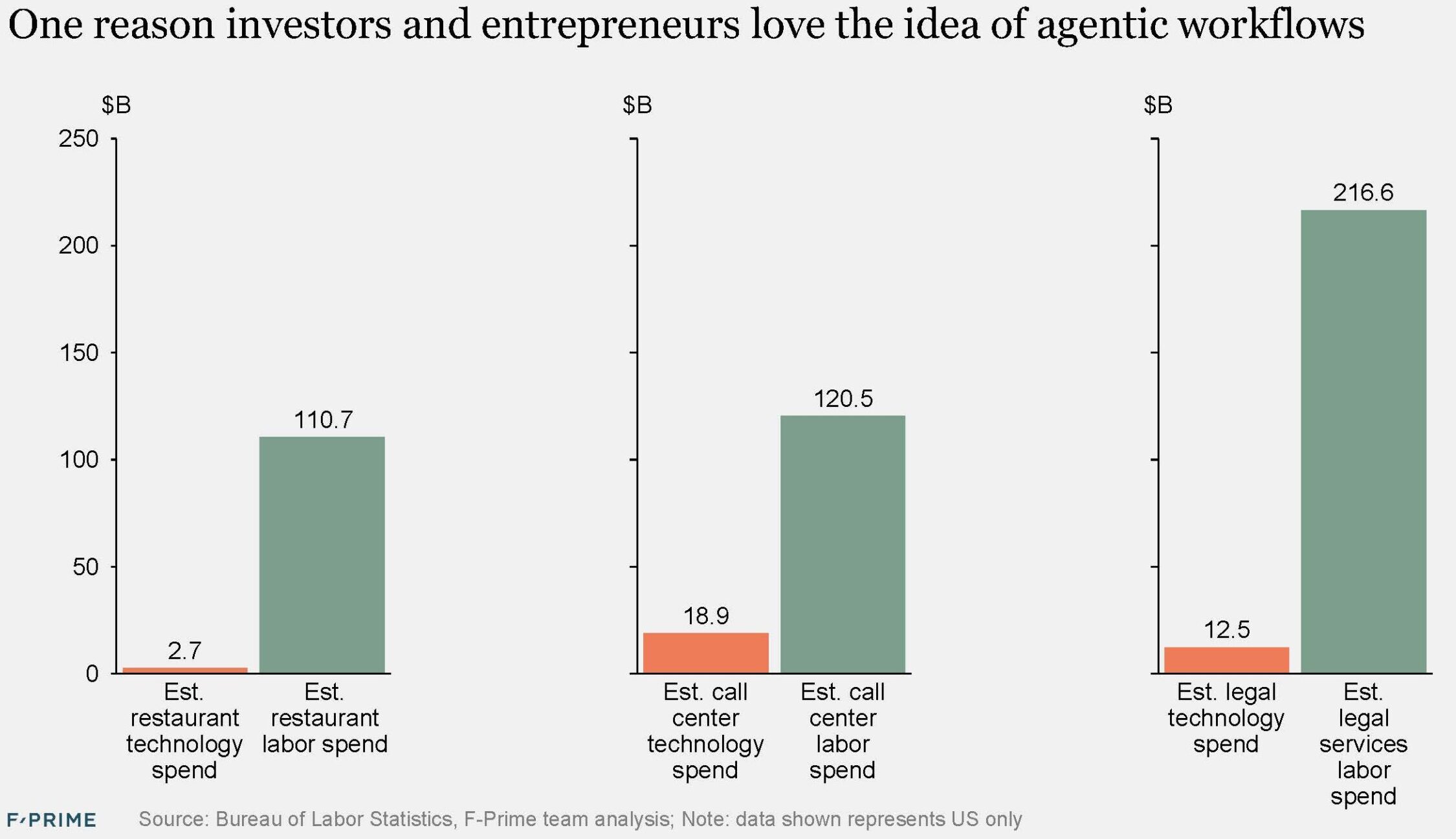
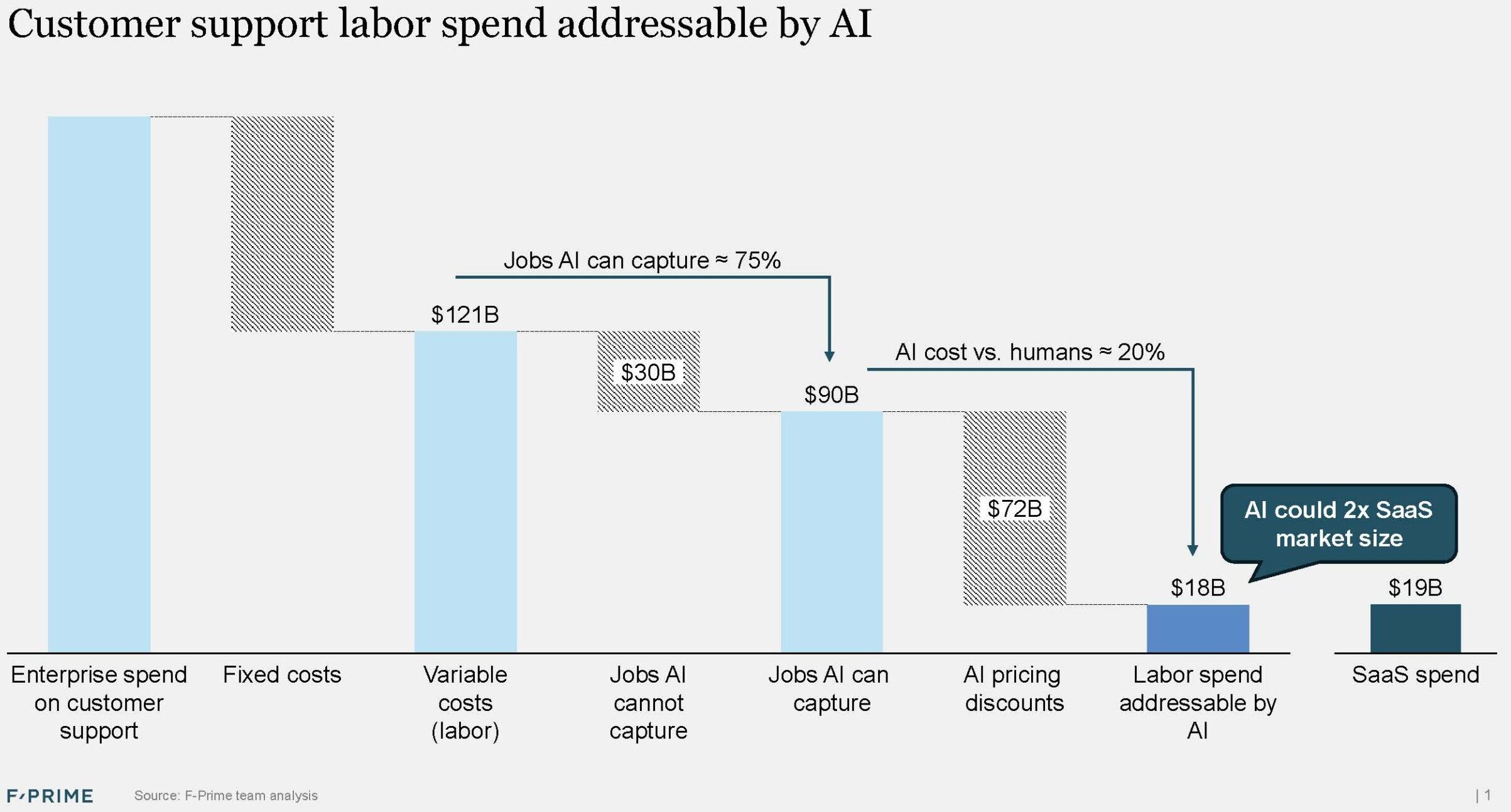
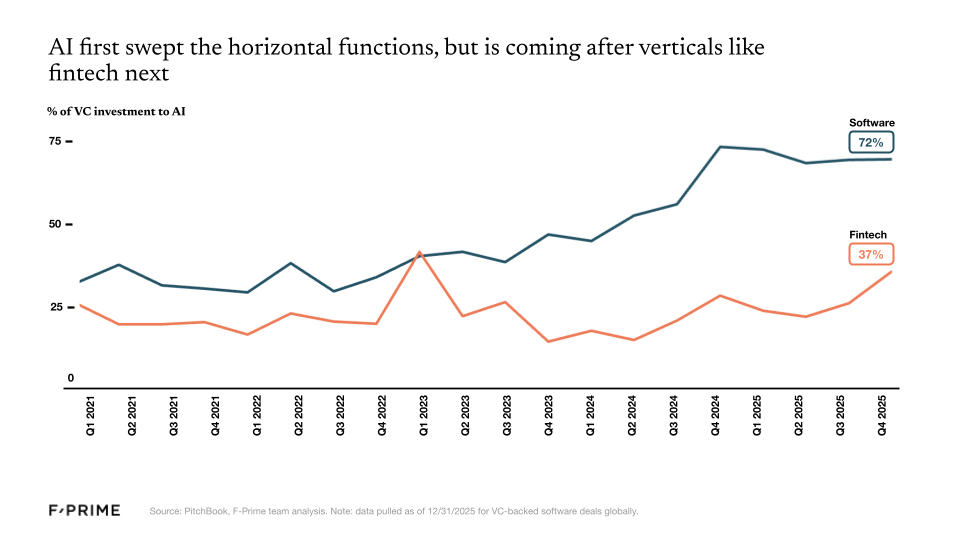
There has been a lot of hype, but 2025 was not the year of AI in fintech. For now it remains a huge, mostly untapped opportunity — financial services is responsible for more than 20% of GDP in the US, but the industry currently has one of the lowest adoption rates for AI agents.
We knew that financial services would lag behind other industries, and for good reason. Accelerated AI adoption works for industries where:
- Context is text-heavy instead of numbers-heavy,
- Existing systems of record are easy to integrate with,
- Stakes are relatively low and imprecise values are still valuable, and
- There is low regulatory exposure.
Financial services strike out on most of these points.
In the broader enterprise software space, nearly three quarters of every dollar invested now goes to AI companies. In the fintech vertical, that number is closer to one third. Since the launch of ChatGPT, fintech has produced a lower percentage of unicorn companies, and those that reach unicorn status are usually not AI-native.
However, we know that financial services is a worthy vertical for AI to tackle. The large models are already building for financial services — OpenAI in payments, Anthropic in financial research — but we believe startups can differentiate on workflow, integrations, and domain knowledge.
By the end of 2025, the primitives for nearly every sector of fintech have been put in place, and they are now ready for a new AI-native application layer to be built on top. We expect the coming years to be exciting and critical ones for AI in financial services and commerce, and it’s time to put the next generation of building blocks in place.
We’ve Never Been More Excited for the Future of Financial Services
If you’re as passionate about fintech as we are, there are so many reasons for excitement.
The regulatory landscape has never been more open to crypto innovation and adoption, and stablecoins are revolutionizing the way money flows around the world. Crypto ETFs are unlocking new pools of capital, and tokenization promises to create a more efficient infrastructure for all asset classes.
It’s still early days for AI in fintech, but the technology is already redesigning the way financial services businesses underwrite risk, design products, allocate capital, and serve their customers. And that’s before we consider AI’s role in determining how consumers earn and save, spend and pay, borrow and build wealth.
The last decade forged the next generation of great financial services companies, and AI is going to create the next.
Go deeper: Access the full report via the F-Prime Fintech Index here.