Data in VC, Part 1: The State of Data, Engineering, and Automation in VC

Data in VC, Part 1: The State of Data, Engineering, and Automation in VC
Venture capitalists are playing a key role in the ongoing boom in artificial intelligence, helping provide capital and guidance for startups seeking and capitalizing on exceptional use cases for AI. So it may come as a surprise to learn that data and AI adoption among VCs themselves has lagged behind the industries they invest in.
I’m a data scientist for F-Prime’s tech fund, and this is the first in a series of three blog posts in which I will explore why AI adoption among VCs has lagged behind the tech industry, how and why that is starting to change, and what the future looks like. As part of this effort, my colleagues over at Eight Roads and I conducted a survey among our fellow data scientists and engineers at other venture capital firms to gauge where they have been most impactful.
A Slow Start in Data Utilization
Data adoption in venture capital has lagged behind other industries. Historically, data sources were limited, expensive, and not very actionable. About 10-15 years ago, VCs primarily used niche data for market trends and consumer behavior, but the accuracy was questionable, and integrating this data into actionable insights was challenging.
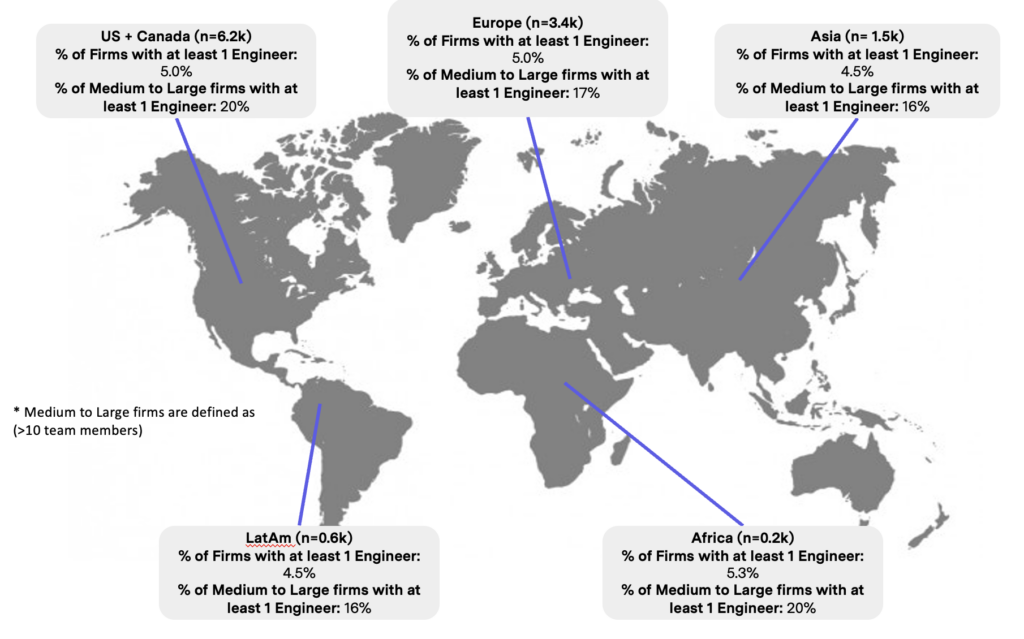
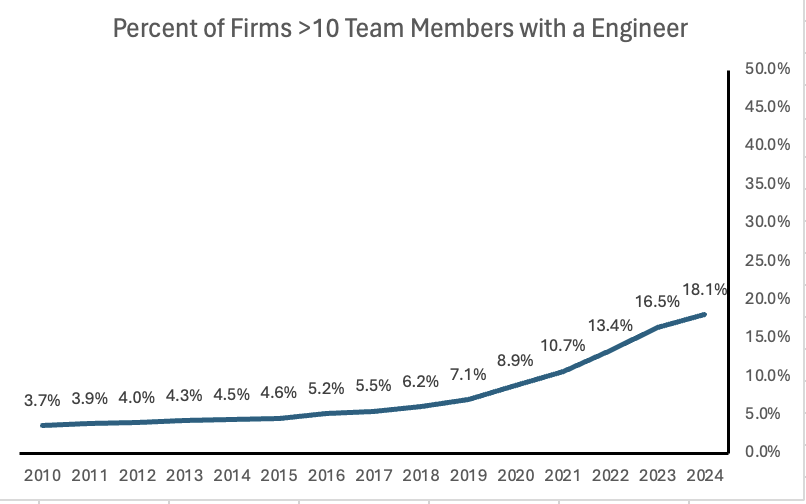
At the same time, there was a scarcity of skilled data and engineering talent. Most of the talent gravitated towards industries with more tangible problems, like software and public finance which, ironically, were often funded by the same VCs. Finally, limited management fees and small fund sizes further constrained VCs, leaving little room for dedicated data or engineering teams. Consequently, only a small fraction of VC firms globally (five percent) have a software engineer, data engineer, or data scientist on staff. Even when looking at medium to large-sized firms (those with more than ten team members), this number rises to just 20 percent.
A Turning Point for Data in VC
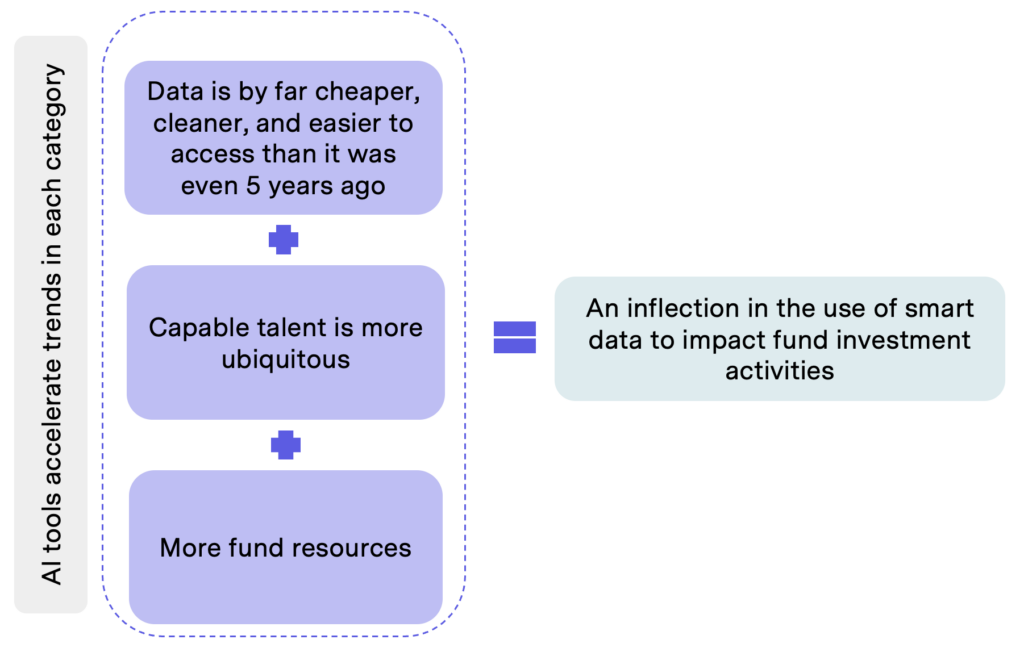
Despite these historically low numbers, we believe VC is approaching an inflection point where concerted data and engineering effort is about to accelerate. Several factors are driving this change:
1. Improved Data Quality and Accessibility: The availability of data has expanded significantly, with data providers mapping more companies and team members, making it easier to track and analyze market trends and potential investment opportunities. Access to non-traditional data sources like credit card transactions and web trends has increased, and data is now more accessible through user-friendly interfaces and APIs. Accuracy and freshness have improved, and increased competition among providers has lowered costs. On top of all of that, GenAI tools further simplify data extraction and structuring, accelerating the trend of making high-quality data more accessible and affordable.
2. Easier Access to High-Quality Talent: The pool of data and engineering talent is growing as more individuals receive formal education in computer science and data science. Technological advancements have abstracted complex tasks like building data pipelines, integrating systems, and developing predictive models, making these processes more accessible even to those with basic training. Again, GenAI tools accelerate trends here, allowing engineers to achieve more with less effort — even average engineers can become “10x engineers.”
3. Increased Management Fees and Larger Fund Sizes: As VC funds grow in size, more resources are available for data and automation initiatives. AI technologies also reduce costs associated with research, due diligence, and operational work, freeing up more resources for data projects. This increased financial flexibility allows VCs to invest in comprehensive data strategies.
The Current State of Data Use in Venture Capital
As more venture capital firms begin to build out their data capabilities, the big question becomes: How are we leveraging data to create a real impact for our firms? We’ve created a framework to think through where firms are focusing their efforts and how we think about the impact of those efforts.
What follows is a high-level overview of the framework and we’ll dive deeper into examples — and explore how the industry thinks about data in VC — in the next two articles.
Where we’re focusing our data/engineering efforts:
1. Sourcing: Use data to identify high-quality, timely investment opportunities.
2. Pipeline Management: Improve the management and prioritization of companies at each pipeline stage through data-driven approaches.
3. Network Management: Map and analyze the firm’s networks to identify gaps and track changes in real time.
4. Company Evaluation: Systems that help more easily diligence companies, with the goal of eventually automating out some diligence task.
5. Portfolio Management: Automate portfolio health tracking, covering performance, competitive landscape, and team changes.
Evaluating Impact: A Four-Tier Framework
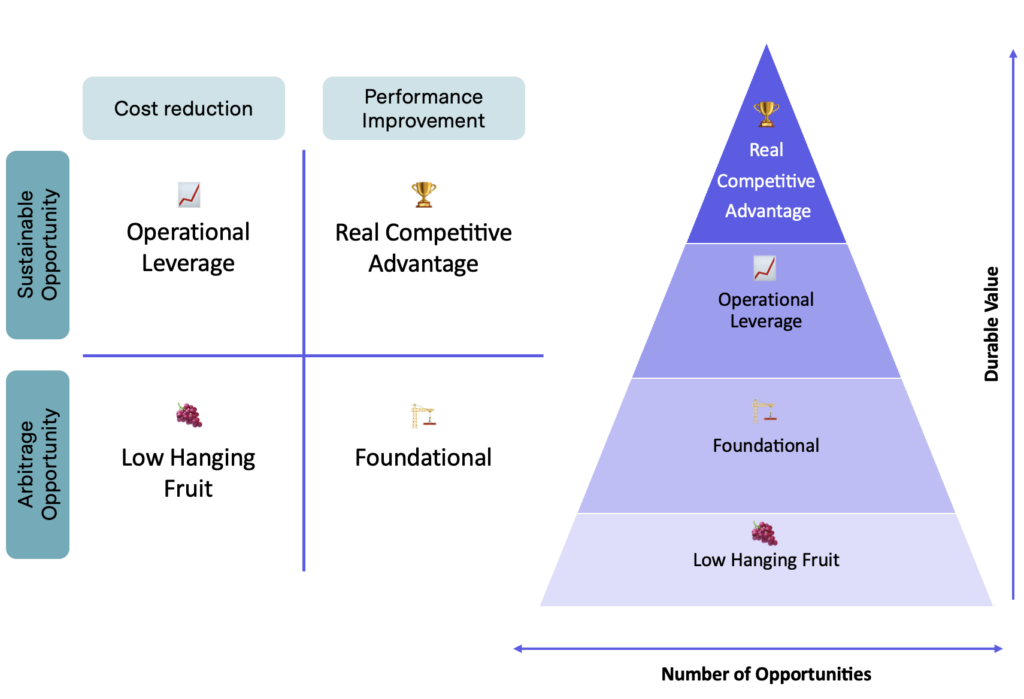
Let’s define some of the terminology you see in the graphic above, and I’ll offer my opinion on how much importance they should hold for VC data scientists and engineers.
Low Hanging Fruit 🍇
Definition: Projects that offer short-term advantages by reducing operational time and costs. These benefits are typically temporary.
Examples: Email/LinkedIn automation (pipeline management), scraping public company lists (sourcing)
Our Opinion: While these are easy to implement and can provide quick wins, their value diminishes as more VCs adopt similar strategies. Over-reliance on these can create dependencies on low-impact solutions, so smart firms will not invest too heavily in “low-hanging fruit” use cases.
Foundational Projects 🏗️
Definition: Essential projects for any VC aiming to build a data-centric approach. These efforts don’t immediately boost efficiency but set the stage for future data-driven initiatives.
Examples: Mapping and filtering networks (network management), setting up a CRM system (pipeline management, network management), extracting and structuring portfolio data (portfolio management), creating a research portal on top of files you’ve collected from startups (company evaluation)
Our Opinion: These projects are vital for enhancing a fund’s capabilities, even though they might not provide immediate competitive benefits. They are necessary to establish a solid base for more advanced data efforts.
Operational Leverage 📈
Definition: Projects that have a lasting impact by reducing time and costs related to specific tasks. These are often customized to fit a firm’s existing workflows developed in the foundational phase.
Examples: Aggregating and synthesizing data for easier company analysis (company evaluation), automating data entry (pipeline management), consolidating relationship data for more informed outreach (network management), synthesizing portfolio health reports (portfolio management)
Our Opinion: These initiatives are worth investing in because they reduce costs and time in the long run, which helps maintain efficient operations, even if they don’t fundamentally change the firm’s overall operations. They typically build upon foundational efforts and tend to be more precise, only improving aspects of workflows.
Real Competitive Advantage 🏆
Definition: Projects that significantly impact operations and differentiate a fund’s strategy. They build on a fund’s existing strengths or offer unique advantages.
Examples: Creating predictive models for niche investments (sourcing), algorithmically finding ways to expand networks (network management), automating insights extraction from diligence documents (company evaluation), identifying emerging trends faster than competitors (sourcing)
Our Opinion: These are the most impactful projects and should be prioritized. They are often tailored to a fund’s specific strategy, making them less generalizable but highly valuable when aligned with a firm’s unique strengths. Focusing on these can create lasting competitive advantages.
Understanding where and how to invest in data initiatives is crucial for VCs looking to stay competitive. That is why we have created this framework; to make it simpler for industry players to understand where to focus efforts to reap the most impact. But in order to get a more holistic understanding of what is important, we sent a set of peer VCs a survey asking how they have leveraged data and how it has impacted their firm, based on this framework. In the next article we will discuss the results of this survey and understand where the majority of value lies when it comes to leveraging data for VC.


